Por favor, mais racionalidade e menos frenesi em relação ao chatGPT (Parte 1 de 2)

As tecnologias nos entusiasmam e muitas vezes nos deslumbram com o que aparentam fazer. Aliás, o escritor de ficção científica Arhur C. Clarke, que escreveu um conto que inspirou “2001, Uma Odisseia no Espaço” (um filme imperdível!) disse certa vez que “Qualquer tecnologia suficientemente avançada é indistinguível da magia”. A IA é um exemplo disso, a começar pelo próprio nome, que leva a antropomorfizar uma técnica de programação de software como se esse conjunto de algoritmos e fórmulas matemáticas, embutidos em chips e processadores, fosse capaz de ser um ser senciente, com intuição, vontade própria, desejos e sentimentos. A questão das chamadas “máquinas inteligentes” é um debate altamente desafiador, pois existem diversas formas de inteligência. A nossa, dos humanos, é diferente dos peixes, mas esses animais possuem alguma forma de inteligência. Um conjunto de algoritmos matemáticos que fazem o que chamamos de sistemas de ML/DL aparentam ter inteligência, mas seus resultados são o produto da interação dos modelos matemáticos com os dados, esses sim, fruto da inteligência humana.
Algumas ideias revolucionárias, chegando às raias do endeusamento da tecnologia, como o conceito da singularidade, proposto por Ray Kurzweil, sugerem que as máquinas serão inteligentes e que nós nos mesclaremos com elas. Seu livro “The Singularity Is Near: When Humans Transcend Biology”, apresenta a proposta que chegaremos a um momento quando o avanço da tecnologia será tão rápido e exponencial, seu impacto tão profundo, que a vida humana será transformada por completo. Nesse ponto a IA excederá a inteligência humana.
Sei que certos debates não chegam a consenso, mas sigo a linha de pensamento que a proposta de Kurzwei é uma crença em um exacerbado “êxtase tecnológico”, que tem permeado a evolução tecnológica, principalmente da IA, e levado muitos a considerarem a IA como algo além do que ela realmente é. Mas atrai adeptos. Verner Vinge, escritor de ficção científica também defende a tese que o crescimento exponencial da tecnologia chegará a um ponto, a singularidade tecnológica, a partir do qual não será mais possível sequer especular sobre as consequências. Em 1993, em simpósio patrocinado pela NASA ele afirmou que em 30 anos, ou seja, agora, em 2023, estaríamos passando por um cataclisma no qual superinteligências mudariam o mundo. Em seu paper “The coming technological singularity: How to survive in the post-human era” ele afirmou “”Within thirty years, we will have the technological means to create superhuman intelligence. Shortly after, the human era will be ended”.

Estamos em 2023 e as previsões cataclísmicas não se concretizaram. Mas, com as novas conquistas da IA, com sistemas LLM (Large Language Models) como DALL-E, Stable Diffusion, LaMDA e chatGPT nos surpreendendo, alguns começam a imaginar que esse futuro talvez já está batendo à nossa porta. Mas, será mesmo? Apesar de algumas projeções futuristas apontarem que esse futuro é praticamente irreversível, eu discordo e quero continuar aqui esse debate. Recentemente escrevi um post “chatGPT: Momento “Jurasssic Park” da IA!” onde iniciei esse questionamento. Agora, vou me aprofundar um pouco mais. O texto é longo e o dividi em dois artigos. Esse é o primeiro. Mas, por que um texto mais aprofundado? Vejo com preocupação que cada vez mais tomamos decisões de forma emocional, com informações muitas vezes superficiais. Essa percepção foi consolidada quando li um estudo “‘We conclude’ or ‘I believe?’ Study finds rationality declined decades ago”. Devemos sim, reconhecer a imprtância da emoção e intuição nas decisões, mas também precisamos da força da racionalidade para nos tornarmos mais assertivos. Essa é minha pequena contribuição para discutirmos com mais racionalidade o que os são os sistemas LLM.
Pensemos, por exemplo, no hype do momento, o chatGPT. O ChatGPT é um sistema generativo LLM (Large Language Model), que é uma tecnologia nova e avançada. Os sistemas generativos ainda estão na fase da emoção, quando o entusiasmo é imenso, superestimamos seu potencial e subestimamos suas limitações e desafios. Muita emoção e pouca informação. O próprio Hype Cycle do Gartner deixa isso bem claro:
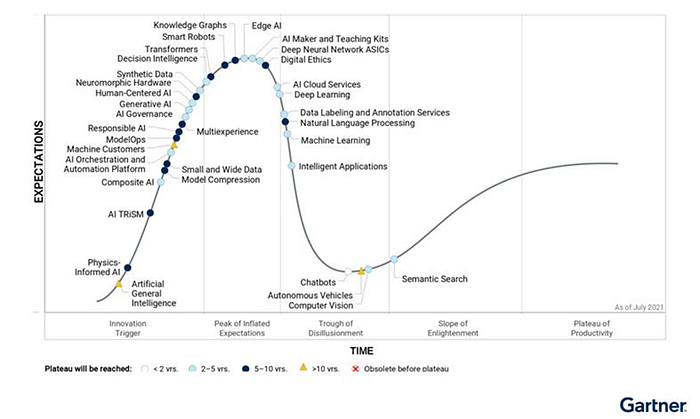
Mas é uma tecnologia que não pode e nem deve ser ignorada. Ferramentas como chatGPT e Dall-E vão se disseminar e isso poderá ter impactos significativos nas profissões criativas e na academia. Por exemplo, poderá mais não ser lucrativo se tornar um advogado que conhece de memória uma grande quantidade de jurisprudência. O sistema fará isso. Mas, em vez disso, as habilidades de síntese e persuasão serão mais críticas para o sucesso. Também se você for um desenvolvedor apenas um pouco melhor que o chatGPT, poderá perder admiração profissional e renda. Os desenvolvedores e escritores excepcionais, que não podem ser facilmente copiados, atrairão mais atenção e status. Por outro lado, pelo aspecto positivo, vai elevar a régua para quem se destacar, deixando a mediocridade para o bot fazer. A diferença entre as máquinas e os humanos será a criatividade. Um chatGPT escreve baseado no que “aprendeu” analisando um imenso volume de dados, mas não tem percepção, não faz inferências e nem pensa “out of the box”. Ele atua quando as regras são claras e “entende” a tarefa, pelo que “aprendeu” no treinamento.Vale a pena ler o artigo “Will chatbots put writers out of business?” para uma discussão mais aprofundada sobre o tema.
Claro, esses são apenas alguns sinais de mudança que estão visíveis. Existem outros aspectos que aprenderemos à medida que essas ferramentas forem se disseminando. Provavelmente alguns efeitos colaterais serão sentidos. Por exemplo, será que esses bots são uma ameaça ao modelo de negócios bilionário que é o padrão de buscas pelo buscador do Google? Bom, pelo sim, pelo não, Google não está inerte. Recentemente, sinais de alerta foram tocados em Mountain View, “Google In Panic mode issues “Code Red” Over ChatGPT”. É provável que o ChatGPT treinado no GPT-4 com RLHF (Reinforcement Learning from Human Feedback — e um paper explicando a técnica aqui) aprimorado vá enfrentar o LaMDA do Google (bastante similar ao chatGPT) em algum momento de 2023 ou início de 2024. Isso poderá mudar o modelo de buscas e afetar diretamente o negócio de mais de 200 bilhões de US$ do Google. Os sistemas como chatGPT ainda apresentam, por vezes, resultados incoerentes, chamados de “alucinações”. A “alucinação” é um obstáculo e tanto para a adoção de modelos sofisticados como ferramentas de pesquisa, tanto mais que o resultado de sua resposta é abstraído do material de origem que o formou, de modo que estabelecer a veracidade de citações e fatos se torna problemático. Mas à medida que avançamos na evolução dos algortimos, provavelmente mitigaremos muitos desses efeitos com alguns algortimos de filtragem. Uma ideia do que está sendo pesquisado pode ser visto em “Preventing ‘Hallucination’ in GPT-3 and Other Complex Language Models”.
Não devemos perder de vista que embora seja um feito de engenharia de sofware de NLP fantástico, o chatGPT continua sendo uma “narrow AI”, ou seja, ele é projetado para uma única tarefa: gerar textos. Ele não analisa imagens de câncer de mama, não joga Go, não faz predições de manutenção de máquinas, não faz detecção de fraudes e nem dirige um veículo. É um sistema de NLP baseado no uso das técnicas de transformer. ChatGPT significa um chat baseado em Generative Pre-trained Transformer (transformador pré-treinado generativo). Como o nome sugere, o software é “generativo”, o que significa que ele gera um novo texto ou imagem com base no que aprendeu com seus data sets de treinamento. Essa é sua tarefa. A arquitetura de modelos transformer foi proposto incialmente em 2017, por pesquisadores do Google Brain e recomendo dar uma lida no paper da proposta: “Attention Is All You Need”. Quem quiser ir mais a fundo, recomendo dois livros:

Portanto, o entusiasmo que estamos às portas de termos uma máquina inteligente, que sabe e tem consciência do que faz, não tem substância. Para se qualificar como IA, um sistema deve exibir algum nível de aprendizado e adaptação. Por esse motivo, sistemas de tomada de decisão, automação e estatísticas não são IA. A IA é amplamente definida em duas categorias: inteligência artificial estreita (“narrow AI”) e inteligência artificial geral (AGI). Até o momento, AGI não existe.
O fato é que o hype sobre sistemas de IA pipocam a todo momento. É importante lembrar que já vivemos um hype similar ao do chatGPT antes: em junho, o então engenheiro do Google, Blake Lemoine, disse em entrevistas que o LLM LaMDA do Google estava “vivo”, e seria senciente. Muita coisa se falou sobre isso, dezenas de artigos foram escritos e hoje, poucos meses depois, nem se comenta mais sobre o assunto. O que distingue o ChatGPT do LaMDA? O fator diferencial é que com o chatGPT o público está interagindo com ele e o manipulando para gerar todos os tipos de experimentos interessantes, enquanto o Google não liberou seu modelo, mantendo-o fechado.
O principal desafio para a criação de uma IA geral é modelar adequadamente o mundo com toda a totalidade do conhecimento, de maneira consistente e útil. Isso é um imenso desafio. A maior parte do que conhecemos hoje como IA é “narrow AI”, onde um sistema específico aborda um problema específico. Ao contrário da inteligência humana, essa inteligência de IA estreita é eficaz apenas na área em que foi treinada: detecção de fraude, reconhecimento facial, gerar textos ou recomendação social.
Ao aumentar o tamanho do modelo e seu corpus de treinamento, os cientistas conseguiram reduzir a frequência dos erros mais flagrantes. Por isso as respostas que o chatGPT oferece são tão impressionantes. Mas os problemas fundamentais não desaparecem, e mesmo os maiores LLMs ainda cometem erros bem bobos. Esse é um problema fundamental que enfrenta qualquer forma de ML. Um computador manipula símbolos. Seu programa especifica um conjunto de regras ou algoritmos com as quais transforma uma cadeia de símbolos em outra ou reconhece padrões estatísticos. Mas não especifica o que esses símbolos ou padrões significam. Para um computador, o significado é irrelevante. O ChatGPT “sabe”, pelo menos na maior parte do tempo, o que parece significativo para os humanos, mas não o que é significativo para si mesmo. É, nas palavras do cientista cognitivo Gary Marcus, uma “mímica que não sabe do que fala”. Continua sendo um “papagaio estocástico”. Ele reproduz palavras e caracteres de volta com base no que viu em textos anteriores, sem compreender seu significado. Ele apenas gera textos semelhantes aos humanos e pelo entusiasmo que as tecnologias, especialmente a IA gera, nós a antropomorfizamos e a consideramos que conversa de igual para igual conosco.
A AGI, por sua vez, funcionaria como os humanos. Por enquanto, o que conseguimos até agora é o uso de redes neurais e “aprendizagem profunda” treinados em grandes quantidades de dados. As redes neurais são inspiradas (não funcionam como…) na maneira como o cérebro humano funciona. Ao contrário da maioria dos modelos de aprendizado de máquina que executam cálculos nos dados de treinamento, as redes neurais funcionam alimentando cada ponto de dados um por um por meio de uma rede interconectada, sempre ajustando os parâmetros.
À medida que mais e mais dados são alimentados pela rede, os parâmetros se estabilizam; o resultado final é a rede neural “treinada”, que pode produzir a saída desejada em novos dados como por exemplo, reconhecer se uma imagem contém um gato, um cachorro ou um coelho.
O avanço significativo na IA hoje está sendo impulsionado por melhorias tecnológicas na maneira como podemos treinar grandes redes neurais, reajustando um grande número de parâmetros em cada execução, isso graças às imensas capacidades computacionais disponíveis nos data centers de computação em nuvem. Por exemplo, GPT-3 (o sistema que alimenta o ChatGPT) é uma grande rede neural com 175 bilhões de parâmetros. O chatGPT não é uma disrupção, mas uma evolução incremental no campo da IA, mais precisamente nas técnicas de NLP, aproveitando o avanço tecnológico da computação.
Um sistema de IA precisa de três coisas para ser bem-sucedido. Primeiro, ele precisa de dados imparciais (sem viés) e de alta qualidade, e uma imensidão deles. Os pesquisadores que constroem redes neurais usam os grandes conjuntos de dados que ficaram disponíveis à medida que a sociedade se digitalizou. Por exemplo, o CoPilot, para apoiar o trabalho dos desenvolvedores humanos, extrai seus dados de bilhões de linhas de código compartilhadas no GitHub. O ChatGPT e outros grandes modelos de linguagem usaram bilhões de documentos de texto.
As ferramentas de texto para imagem, como Stable Diffusion e DALL -E2 usam pares imagem-texto de conjuntos de dados como LAION-5B. Os modelos de IA continuarão a evoluir em sofisticação e impacto à medida que digitalizamos mais de nossas vidas e fornecemos a eles fontes de dados alternativas, como dados simulados ou dados de configurações de jogos como o Minecraft.
A IA também precisa de infraestrutura computacional para um treinamento eficaz. À medida que os computadores se tornam mais poderosos, os modelos que agora exigem esforços intensivos e computação em larga escala poderão, no futuro, ser manuseados localmente. O Stable Diffusion, por exemplo, já pode ser executado em computadores locais em vez de ambientes de nuvem.
A terceira necessidade da IA são os modelos e algoritmos aprimorados. Os sistemas orientados por dados continuam a progredir rapidamente em domínio após domínio, no que se pensava ser o território da cognição humana.
No entanto, como o mundo ao nosso redor muda constantemente, os sistemas de IA precisam ser constantemente retreinados usando novos dados. Sem essa etapa crucial, os sistemas de IA produzirão respostas factualmente incorretas ou não levarão em consideração novas informações que surgiram desde que foram treinados.
As redes neurais não são a única abordagem para IA. Outro campo proeminente na pesquisa de inteligência artificial é a IA simbólica — em vez de digerir enormes conjuntos de dados, ela se baseia em regras e conhecimentos semelhantes ao processo humano de formar representações simbólicas internas de fenômenos específicos.
Mas, na última década, o interesse dos projetos de IA se inclinou fortemente para as abordagens baseadas em dados, e os “pais” do aprendizado profundo moderno (Yoshua Bengio, Geoffrey Hinton e Yann LeCunn) recentemente receberam o Prêmio Turing, o equivalente ao Prêmio Nobel na ciência da computação.
Dados, computação e algoritmos formam a base do futuro da IA. Todos os indicadores indicam que um rápido progresso será feito em todas as três categorias no futuro previsível. Mas, apesar dos impressionantes avanços que aparentemente colocam os computadores ao alcance da inteligência humana, suas operações internas desmentem o hype: os computadores não são inteligentes como os humanos. Embora eles possam, por meio da programação e da engenharia inteligente (ambas providas por humanos!), produzir resultados que associamos à inteligência, eles não entendem o que estão fazendo ou vendo. Muitas vezes nós tratamos nossas criações algorítmicas como se estivessem vivas, proclamando que nosso algoritmo “aprendeu” uma nova tarefa, em vez de meramente induzir um conjunto de padrões estatísticos de um conjunto de dados de treinamento escolhido a dedo, sob a supervisão direta de um humano, que escolheu quais algoritmos, parâmetros e fluxos de trabalho usar para construí-lo.
A tecnologia de IA, (vamos continuar usando o termo, cunhado em 1956, pelo fato de já estar disseminado e pela falta de outro), vai produzir um conjunto extremamente poderoso de ferramentas que nos ajudarão em muitas coisas. Mas são apenas isso, ferramentas. A inteligência artificial é o produto da criatividade e imaginação humana com o uso de rígidos e precisos modelos matemáticos inseridos em computadores.
Claro, o debate não termina aqui. Vai continuar no próximo post, que pode ser lido aqui.
